
buarki
FollowSite Reliability Engineer, Software Engineer, coffee addicted, traveler
Snap out of layers: Why 'slices' are a better way to streamline your code organization
November 4, 2023
2060 views
Share it
In the following sections of this article, we will explore alternative design approaches that address challenges introduced by using "Layered Architecture". These solutions aim to make business intentions more explicit, reduce tight coupling, and improve the overall maintainability of your codebase. By the end, you will have a clearer understanding of how to structure your backend applications for greater efficiency and ease of development.
A case of study: how code is structured most of the time on backend applications?
I must say that it is very common to open a brand new project and see the following structure:
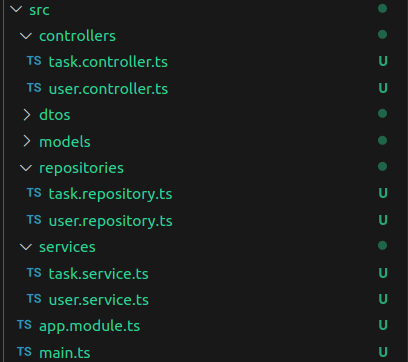
Above image represents a typical application using Layered Architecture. This mode of organizing code focuses on organizing code by technical concerns, such as the controllers, services, repositories and so on.
I have worked on a plenty of projects using that exact same structure and they worked fine I must say. But pretty much all the time I got a new one like this I asked myself: which features is this project delivering? how it is supporting the business needs?
Organizing code by technical concerns doesn't make it explicit which business problems the code is trying to address. To figure it out you must dig into it probably starting on the controller, checking which services it calls, which repositories are used by services etc.
Implications of such design
Figuring out what such systems do usually will take some time as said before, and it'll probably require a few code walkthroughs with a coworker that has more knowledge about it. As consequence it has a direct impact in the time to deliver new features or fixies on code.
Such design also pushes for tight coupling between the system components because soon a cross-entity feature will pop up, such as "listing all tasks of an user", and the application will end up having the situation where "user-service" is calling the "task-repository". The intention behind it is fare and good, is called Don't Repeat Youself (DRY). DRY principle encourages reusing code to reduce duplication. But applying it in certain scenarios, specially in cases of over-reuse, makes things so coupled that is very hard to modify a piece of code not having unintended side effects somewhere else, because as code is being shared and used to implement different features any modification done will not be isolated.
Furthermore, the tight coupling between components in this traditional layered architecture can also become a significant pain point when multiple developers are collaborating on the same codebase. When different team members are working on different parts of the system that share tightly coupled dependencies, the likelihood of encountering merge conflicts significantly increases. As a consequence, developers find themselves in a race to resolve these conflicts. This race involves inspecting and manually merging conflicting code, which can be a time-consuming and error-prone process. Not only does it slow down the development process, but it also introduces the risk of introducing unintended bugs or breaking other parts of the system during conflict resolution. In essence, the tightly coupled nature of the traditional architecture exacerbates the problem of merge conflicts, making it an issue that can no longer be ignored when multiple team members are actively working on the same codebase. This issue can result in a domino effect, affecting the development timeline and potentially compromising code stability.
In the end, the main consequence of such design is that business intentions gets obfuscated and the comprehension of the project as a whole will rely on the deep analysis of code.
As a concrete example we can assume that the features that the service from print must cover are: (1) the user needs to sign up; (2) the user needs to login; (3) user can create a task, like on Jira; (4) user can edit the task description; (5) user can delete a task; (6) and the user can list its own created tasks. If we breakdown the layered application it might look like bellow image:
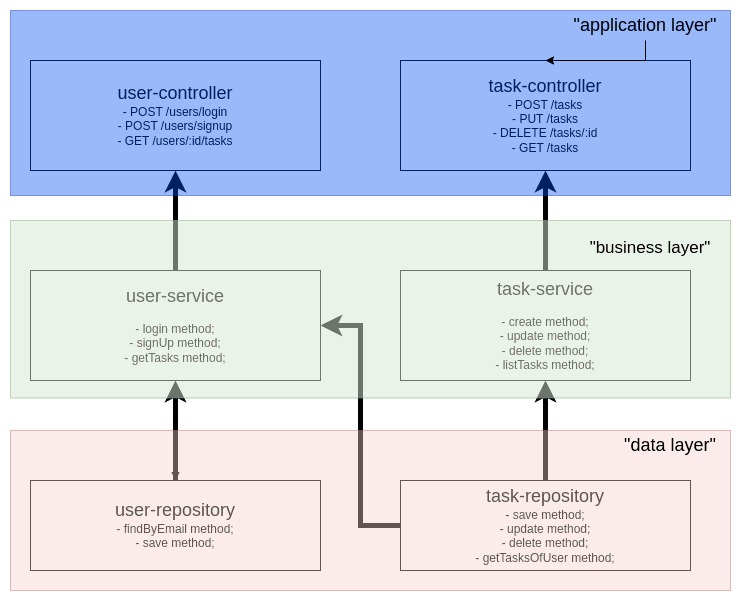
The feature "list all user's tasks" implemented by the "user-service" requires a query implemented by the "task-repository" which creates a coupling between them. The reason for that is: both "user-service" and "task-service" needs to do that listing, so to avoid duplicating code we make both use the same implementation (DRY principle). Now suppose that the usage of such task listing on the "task context" changes and now it should be able to list tasks of users active, inactive or both. In order to keep the "user-service" using "task-repository" this modification will also be propagated to it, and it's easy to see where it leads us: a truly spaghetti code :)
A suggestion to improve code organization: Vertical Slice Architecture (VSA)
If you consider the three layers presented as part of a big cake we could also start looking at our features as slices of it. And that way, all technical concerns needed for each feature would be grouped together ensuring minimal side effects in case of modifications. Take a look at bellow pictures:
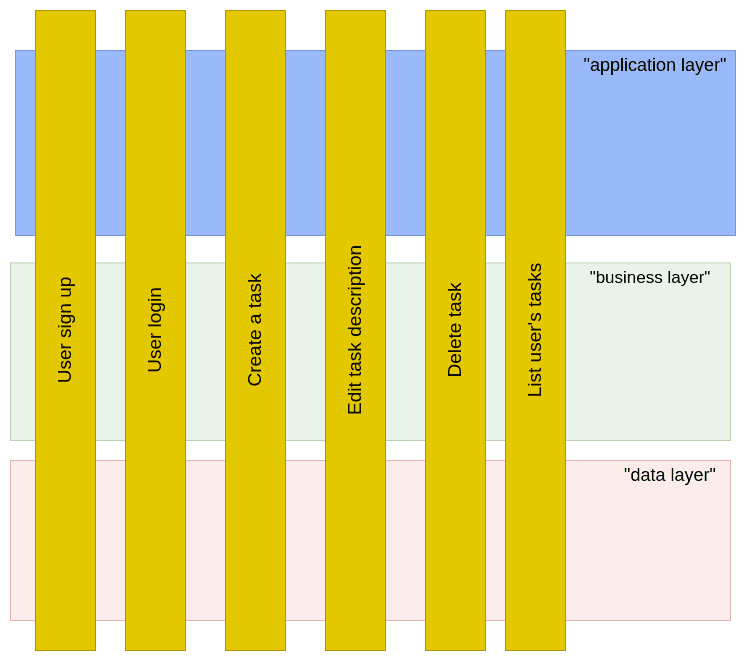
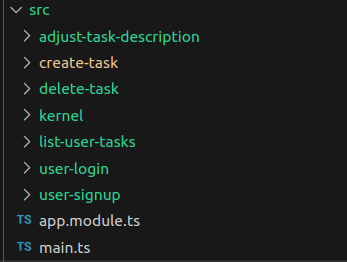
The first notable difference we must point is now the code structure is more close to the feature requirements, actually we have a 1:1 match of how users in fact use the system and probably how the Product Owner of the team lists the available features :)
By following this approach we enforce the system features to be treated as independent components that can be created and evolve independently. We also push for a lower coupling between the system components making the slices more cohesive. The time to grasp what the system does also decreases as the top level navigation is more related to the feature requirements per se, and one doesn't need to understand the system as a whole, as the overall feature's code now have clear boundaries. And for sure, adding new features becomes a more straightforward exercise with a much lower risk of unintended side effects.
Even before you ask: yes, some things for sure will be shared between slices
While reading the general idea of VSA one may think it implies the project to have nothing shared at all between slices, but that is not the case. In case you find yourself seeing duplicated code between two slices there's no problem in extracting it into a shared package, usually called kernel or shared. But you'll also realize that this won't be so frequent, because for such scenario happen the piece of code to be shared must be doing pretty much the exact business related action (something expected to not happen so frequently while organizing code by features).
Summarize
There's no silver bullet while building software. From the experiences I had scaling system using vertical slice architecture I must say it gave to me and to the teams I was working on flexibility to ship new features fast and it made it easy to apply fixies and reafactorings isolated with minimal side effects and specially during the maintenance phase.
For sure for newcomers of this design approach it will have some initial friction, but in a few iterations the general idea will stuck, and in case you need some mentoring on that you can reach me out ;)